
Recent months have witnessed rapid progress in 3D generation based on diffusion models. Most advances require fine-tuning existing 2D Stable Diffsuions into multi-view settings or tedious distilling operations and hence fall short of 3D human generation due to the lack of diverse 3D human datasets. We present an alternative scheme named MVHuman to generate human radiance fields from text guidance, with consistent multi-view images directly sampled from pre-trained Stable Diffsuions without any fine-tuning or distilling. Our core is a multi-view sampling strategy to tailor the denoising processes of the pre-trained network for generating consistent multi-view images. It encompasses view-consistent conditioning, replacing the original noises with ``consistency-guided noises'', optimizing latent codes, as well as utilizing cross-view attention layers. With the multi-view images through the sampling process, we adopt geometry refinement and 3D radiance field generation followed by a subsequent neural blending scheme for free-view rendering. Extensive experiments demonstrate the efficacy of our method, as well as its superiority to state-of-the-art 3D human generation methods.
Pipeline
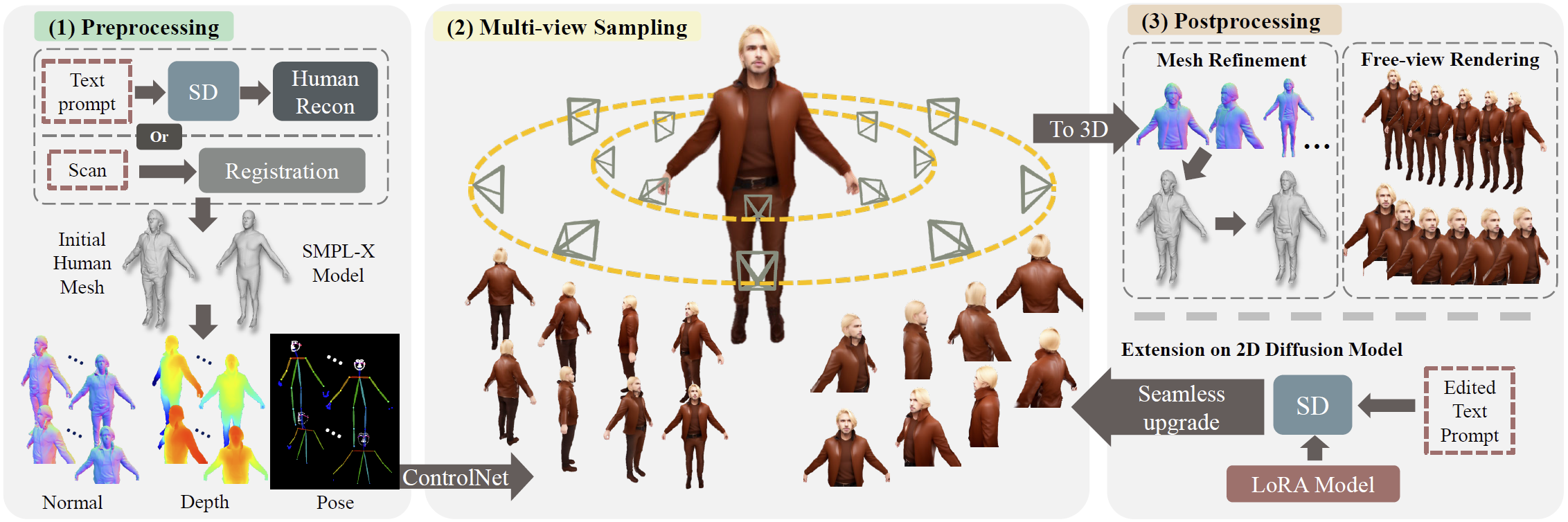
The core of our MVHuman is a novel multi-view sampling process to simultaneously sample multiple view-consistent images with the aid of a coarse human geometry proxy. Specifically, we construct ``consistency-guided noise'' in sampling steps to gradually denoise the individual initial random noises of multiple views into consistent ones. With the multi-view sampling above, we carefully generate high-quality human images from multiple view points which enable reconstructing detailed 3D geometry and generating neural radiance fields followed by a neural blending scheme for free-view rendering.
Results
The generation results of MVHuman, including characters from games/movies, celebrities, and customized humans.
Comparison
Application
Based on a pre-trained 2D stable diffusion model, text-guided editing and LoRA models can be seamlessly integrated into our method.
Social Impact
When researching generative technologies, we concern about their potential infringements on intellectual property. There should be heightened legal restrictions on the applications of such technologies. Furthermore, gender and cultural diversity are crucial. It is necessary for any generative technology to ensure inclusivity and avoid stereotypes. In this paper, all our results are carefully selected based on these principles.